İstatistikte Sıklıkçı (Frequentist) ve Bayesçi Yaklaşımlar
Çeviren: Ahmet Diril (e-posta)
İstatistik neyle uğraşır?
Belirli bir grup nesneden bazı veriler elde ettiğinizi düşünün. Bu bir insan grubu içindeki bireylerin boyları, bir kedi sürüsü içindeki kedilerin ağırlıkları, bir buket çiçekteki yaprakların sayısı vb olabilir.
Bu tür gruplara örneklem (sample) denir ve elde edilen veriler iki şekilde kullanılabilir. Yapabileceğiniz en basit şey, örneklemin ayrıntılı bir açıklamasını vermektir. Örneğin, bazı yararlı özelliklerini hesaplayabilirsiniz:
- Örneklemin ortalaması
- Örneklemin yayılımı (spread) (veri noktalarının birbirinden ne kadar farklı olduğu); varyansı olarak da bilinir
- Belirli bir değerin üstünde veya altında yer alan kişilerin sayısı veya yüzdesi (ör. boyu 180 cm'nin üzerinde olan kişilerin sayısı)
- Vb.
Bu nicelikleri (sayısal değerleri) yalnızca örneklemi özetlemek için kullanıyorsanız, bu tip hesaplamalarla ilgilenen disiplin tanımlayıcı istatistiktir (descriptive statistics).
Peki ama ya örneklemin özelliklerinden daha fazla (daha genel) bir şey öğrenmek isterseniz? Ya sadece bu örneklem için değil aynı zamanda örnekleri aldığınız popülasyon (ana grup) için de geçerli olan bir model (pattern) bulmak isterseniz? Bu tür genellemelerle ilgilenen istatistik dalı, çıkarımsal istatistiktir (inferential statistics) ve bu yazının ana odağıdır.
Çıkarımsal (çıkarsamalı, inferential) istatistikteki iki genel “felsefe” (düşünce akımı, yaklaşım) sıklıkçı (frequentist) çıkarım ve Bayesçi çıkarımdır. Aralarındaki temel farkları, formüle ettikleri soru tipleri ve bunları cevaplama yolları üzerinden ortaya koyacağız.
Ama önce, çıkarımsal istatistiğe kısa bir girişle başlayalım.
İçindekiler
- Çıkarımsal istatistik
- İnteroküler travmatik test
- Çıkarımsal istatistiğin 3 hedefi
- Sıklıkçı ve Bayesçi istatistik ve bunların karşılaştırılması
- Sıklıkçı ve Bayesçi olasılık tanımlarına genel bakış
- Parametre tahmini/kestirimi (estimation) ve veri tahmini (prediction)
- Özet
Çıkarımsal istatistik
Dünyadaki tüm yetişkin erkekler ve kadınlar arasındaki ortalama boy farkını bulmak istediğinizi varsayalım. İlk fikriniz doğrudan ölçmek olacaktır. Mevcut dünya nüfusu yaklaşık 7,13 milyar, bunun 4,3 milyarı yetişkin. 4,3 milyar kişinin tek tek boylarını ölçer misiniz? Bence de olmaz. Bu en azından pratik değil.

Daha gerçekçi bir plan, gerçek farkın bir tahminiyle/tahminiyle yetinmek olacaktır. Yani, dünyadaki farklı alt popülasyonlardan yetişkin erkek ve kadınların örneklerini toplar ve onlardan tüm erkeklerin ve tüm kadınların ortalama boylarını çıkarmaya/çıkarsamaya çalışırsınız.
İşte çıkarımsal istatistik terimi de böyle ortaya çıktı. Elinizde tamamı çalışılamayacak kadar büyük bir popülasyon var, bu nedenle o popülasyondan alınan örneklerden popülasyon özelliklerini tahmin etmek için istatistiksel teknikler kullanırsınız.
Örnekler/örneklemler (sample) ve popülasyonlar arasındaki ayrım hakkında biraz daha fazla bilgi edinmek istiyorsanız, linkteki yazımın olasılık dağılımlarıyla ilgili bölümünü okuyabilirsiniz.
İnteroküler travmatik test (Göze çarpma testi, Aşikarlık testi)
Bazı özel durumlarda, sadece bir model (pattern) veya fark olup olmadığını bilmek isteyebilirsiniz. İki grup arasındaki farkın tam büyüklüğü gibi özellikler sizin için önemli değildir. Bu gibi durumlarda, kullanabileceğiniz en basit çıkarım tekniği bazen şaka yollu olarak interoküler travmatik test (IOTT) olarak adlandırılır. Bu testi, model/kalıp (pattern) iki gözünüzün tam ortasına çarpacak kadar açık olduğunda uygularsınız!
Örneğin, şirket CEO'ları ve şirket temizlik görevlileri arasındaki yıllık maaş farklarını karşılaştırıyorsanız, ikisi arasında büyük bir fark/uçurum olduğu sonucuna varmak için istatistikte uzman olmanıza gerek yoktur.
Tahmin edebileceğiniz gibi, IOTT'nin gerçek dünyadaki uygulama alanı çok sınırlıdır. Birçok farklılık, bu tür doğrudan yollarla tespit edilemeyecek kadar inceliklidir/göze çarpmaz. En ilginç kalıpların çoğunun basit “evet / hayır” soruları ile cevaplanamadığını da söylemek gerek. Bu karmaşık durumlarla başa çıkmak için birçok istatistiksel teknik geliştirilmiştir.
Çıkarımsal istatistiğin 3 hedefi
Çıkarımsal istatistikte, bir popülasyondan alınan bir örneklemden gelen verilerden popülasyon hakkında bir şey çıkarmaya çalışırız. Ama çıkarmaya çalıştığımız şey tam olarak nedir?
Çıkarımsal istatistikteki yöntemlerin tümü aşağıdaki 3 hedeften birine ulaşmayı amaçlar.
Parametre tahmini/kestirimi/hesaplaması (estimation)
Olasılık dağılımları bağlamında parametre, dağılımın özelliklerini belirleyen (genellikle de bilinmeyen) bir sabittir.
Örneğin, normal dağılımın parametreleri, ortalama ve standart sapmasıdır. Ortalama, “çan eğrisinin” tam ortasındaki değeri ve standart sapma bu eğrinin genişliğini belirler. Bu nedenle, verilerin normal dağılıma sahip olduğunu biliyorsanız, parametre tahmini, ortalama ve standart sapmasının gerçek değerlerini öğrenmeye çalışmak anlamına gelir.
Veri tahmini/öngörüsü (prediction)
Bu amaç için, genellikle belirli parametreleri önceden tahmin etmiş (hesaplamış) olmanız gerekir. Sonra bunları kullanarak gelecekteki verileri tahmin edersiniz.
Örneğin, bir örneklemdeki kadınların boylarını ölçtükten sonra, tüm yetişkin kadınlar için dağılımın ortalamasını ve standart sapmasını tahmin edebilirsiniz. Ardından, bu değerleri kullanarak rastgele seçilen bir kadının belirli bir değer aralığında bir boya sahip olma olasılığını tahmin edebilirsiniz.
Tahmin ettiğiniz (hesapladığınız) ortalamanın 160 cm civarında olduğunu varsayalım. Ayrıca standart sapmanın yaklaşık 8 cm olduğunu tahmin ettiğinizi varsayalım. Bu durumda, popülasyondan rastgele bir yetişkin kadın seçerseniz, onun 152 - 168 cm arasında bir boya sahip olmasını bekleyebilirsiniz (ortalamadan 3 standart sapma uzakta). Ortalamadan daha fazla sapan boylar (ör. 146 cm, 188 cm veya 193 cm) uzaklaştıkça daha az olasıdır.
Model karşılaştırması
Ayrıntılara girmeden bu hedeften kısaca bahsediyorum çünkü bu, diğer yazılarda ele alacağım biraz daha ileri seviye bir konu (başlangıç için, doğal olarak model karşılaştırmasına izin veren inanç yayılımı (belief propagation) için bir yöntem olan Bayesçi inanç/güven ağları (belief networks) hakkındaki yazımı okuyabilirsiniz).
Kısaca söylersek, model karşılaştırması, 2 veya daha fazla model arasından gözlemlenen verileri en iyi açıklayan istatistiksel modeli seçme işlemidir. Basitçe model, verileri oluşturan süreç/olaylar hakkında bir dizi önermedir. Örneğin, bir model bir yetişkinin boyunun aşağıdaki gibi faktörlerle belirlendiğini varsayabilir:
- Biyolojik cinsiyet
- Genler
- Beslenme
- Fiziksel egzersiz
İstatistiksel bir model, bu faktörler ile açıklanacak veriler arasında belirli bir ilişki önerir. Örneğin, “genetik bileşenler boyu fiziksel egzersizden daha fazla etkiler” gibi.
İki model, faktörlerin verileri etkileme gücünü farklı önerebilir veya faktörler arasındaki belirli bir etkileşim olduğunu önerebilir vb. Bu durumda, gözlemlenen verilere en iyi uyan model en doğru olarak kabul edilir.
Sıklıkçı ve Bayesçi istatistik - karşılaştırma
Bu iki ekol arasındaki farklar, olasılık kavramını yorumlamalarından kaynaklanmaktadır.
Sıklıkçı ve Bayesci olasılık tanımlarına genel bakış
Daha önceki bir yazıda, olasılığın 4 ana tanımından bahsettik:
- Uzun vadeli sıklıklar (frekanslar/tekrarlanmalar)
- Fiziksel eğilimler (tendency) / temayüller (propensity)
- İnanç/güven dereceleri (degrees of belief)
- Mantıksal destek dereceleri
Sıklıkçı çıkarsama ilk tanıma dayanır, oysa Bayesci çıkarsama ise tanım 3 ve 4'e dayanır.
Özetle sıklıkçı olasılık tanımına göre, sadece tekrarlanabilir rastgele olayların (havaya bir metal para atmanın sonucu gibi) olasılıkları olabilir. Bu olasılıklar, söz konusu olayların uzun dönem gerçekleşme sıklığına eşittir.
Sıklıkçılara göre, hipotezlerin veya genel olarak sabit ama bilinmeyen değerlerin olasılıkları olamaz. Bu, dikkatle incelenmesi gereken çok önemli bir noktadır. Bunu görmezden gelmek, sıklıkçı analizlerin yanlış yorumlanmasına yol açabilir.
Aksine, Bayesçiler olasılığı daha genel bir kavram olarak görürler. Bir Bayesci olarak, herhangi bir olay veya hipotezdeki belirsizliği temsil etmek için olasılıklar kullanılabilir. Bu yaklaşımda, tekrarlanamayan olaylara (2016'da ABD başkanlık yarışını Hillary Clinton’ın kazanması gibi) olasılıklar atamak tamamen kabul edilebilir bir durumdur. Gelenekçi sıklıkçılar, bu olay tekrarlanabilir olmadığı için bu olasılıkların anlamsız olduğunu iddia edecektir. Yani, seçim sürecini sonsuz sayıda tekrarlayamaz ve bunlardan Hillary Clinton'ın kazandıklarının oranını hesaplayamazsınız.
Farklı olasılık tanımları hakkında daha fazla bilgi için, yukarıda bağlantısını verdiğim yazıyı okumanızı tavsiye ederim.
Parametre tahmini/kestirimi/hesaplanması (estimation) ve veri tahmini/öngörüsü (prediction)
Bu bölüm hakkında daha fazla bilgi için, olasılık dağılımları konusundaki giriş niteliğindeki yazıma göz atabilirsiniz.
Aşağıdaki örneği ele alalım. Yetişkin kadınların ortalama boylarını tahmin etmek/hesaplamak istiyoruz. İlk olarak, boyun normal dağılıma sahip olduğunu varsayıyoruz. İkinci olarak, standart sapmanın mevcut olduğunu ve onu tahmin etmemiz gerekmediğini varsayıyoruz. Bu durumda, tahmin etmemiz gereken tek şey dağılımın ortalamasıdır (mean).
Sıklıkçıların yaklaşımı
Bu probleme sıklıkçı bir yaklaşım nasıl olurdu? Şu şekilde bir akıl yürütme yapılırdı:
“Ortalama kadın boyunun ne olduğunu bilmiyorum. Ancak, bu değerin (rastgele değil) sabit bir değer olduğunu biliyorum. Bu nedenle, ortalamanın belirli bir değere eşit veya başka bir değerden daha küçük/ daha büyük olma olasılığından bahsedemem. Yapabileceğim şey popülasyondan alınan bir örneklemden alınan verileri toplamak ve bunun ortalamasını verilerle en tutarlı değer olarak tahmin etmektir.”
En sonda bahsedilen değere maksimum olabilirlik tahmini denir. Bu değer, verilerin dağılımına bağlıdır ve hesaplanmasıyla ilgili ayrıntılara girmeyeceğim. Bununla birlikte, normal dağılıma sahip veriler için durumu oldukça basittir: popülasyon ortalamasının maksimum olabilirlik tahmini, örneklemin ortalamasına eşittir.
Bayes yolu
Öte yandan bir Bayesci farklı bir mantık yürütür:
“Ortalamanın sabit ve bilinmeyen bir değer olduğunu kabul ediyorum, ancak belirsizliği olasılıkla temsil etmede hiçbir sorun görmüyorum. Bunu, ortalamanın olası değerleri üzerinde bir olasılık dağılımı tanımlayarak yaparım ve bu dağılımı güncellemek için örneklem verilerini kullanırım.”
Bayesçi bir ortamda, yeni toplanan veriler parametre üzerindeki olasılık dağılımını daraltır. Daha spesifik olursak, parametrenin gerçek (bilinmeyen) değeri etrafında daraltır. Güncelleme işlemini Bayes teoremini uygulayarak yaparsınız:
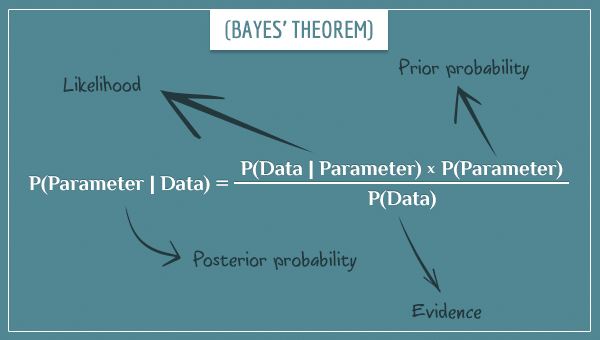
"öncül" (prior), "ardıl" (posterior), "olabilirlik" ve "kanıt" terimlerini gösteren oklarla denklem olarak Bayes teoremi yukarıda verilmiştir.
Olasılık dağılımının tamamını güncellemenin yolu, parametrenin olası her değerine Bayes teoremini uygulamaktır.
Bayes teoremine aşina değilseniz, giriş niteliğindeki yazıya ve bu yazıya bir göz atabilirsiniz. Teorem ve bunun türetilmesi hakkında bazı bilgileri bulacaksınız. Ve gerçekten Bayes teoreminin nasıl kullanıldığını görmek istiyorsanız, bu yazı tam size göre. Bu yazıda, her havaya para atılmasından sonra olasılık dağılımının tümünü güncelleyerek bir paranın bias’ının tahminini/hesaplanmasını gösterdim.
Sıklıkçılar Bayesçi yaklaşıma ana itirazı, öncül/önceki (prior) olasılıkların kullanılmasıdır. Onların itirazı, bu değerleri belirlemede her zaman öznel (sübjektif) bir unsur olduğudur. Paradoksal olarak, Bayesliler öncül olasılıkların kullanılmamasını sıklıkçı yaklaşımın en büyük zayıflıklarından biri olarak görürler.
Her ne kadar bu, kesin bir cevap vererek sonlandırabileceğiniz bir tartışma olmasa da, gerçek tam ortada bir yerde de değildir. Gelecekte, öncül olasılıkları kullanmanın veya kullanmamanın matematiksel ve uygulamadaki sonuçları üzerine bir yazı yazacağım.
Veri tahmini (data prediction)
Burada, sıklıkçı ve Bayesci yaklaşımlar arasındaki farklılık, parametre kestirimindeki farklılığa benzerdir. Yine, sıklıkçılar olası parametre değerlerine olasılık atfetmez/atamaz ve yeni veri noktalarını tahmin etmek için bilinmeyen parametrelerin (maksimum olabilirlik) nokta tahminlerini kullanırlar.
Bayesçiler ise olası parametre değerleri üzerinde tam bir ardıl (posterior) dağılıma sahiptir. Bu da onlara, tahmini en olası değere dayandırmak yerine, tam ardıl dağılım üzerinden integral alarak tahmindeki belirsizliği hesaba katma imkanı sağlar.
P değerleri ve güven aralıkları
Sıklıkçılar, gerçek parametre değerindeki belirsizliği olasılıksal olarak ele almaz/hesaplamaz. Ancak bu, belirsizliği sihirli bir şekilde ortadan kaldırmaz. Maksimum olabilirlik tahmini yanlış olabilir ve aslında çoğu zaman yanlıştır da! Belirli bir tahminin/kestirimin doğru olduğunu varsaydığınızda, ancak gerçekte böyle olmadığında, bir hata yapmış olursunuz. Sonuç olarak, bu uzun dönem hata oranlarını ölçmek ve sınırlamak için iki matematiksel tekniğin gelişmesine yol açmıştır:
- sıfır/boş (null) hipotez anlamlılık testi (NHST) ve bununla ilgili p-değerleri kavramı
- güvenilirlik aralığı
Genel fikir bir tahminde bulunmak, sonra tahmin hakkında sadece belirli koşullar altında geçerli olan bir varsayımda bulunmaktır. Bu koşullar, uzun dönem hata oranını bir değer ile (genellikle %5 veya daha düşük) sınırlayacak şekilde seçilir.
Bu konuyla ilgili daha önceki bir yazıda (p değerlerinin doğru yorumlanmasının yanı sıra) NHST’nin kontrol ettiği hata oranlarının türlerinden bahsettim. Ancak, p değerlerine aşina değilseniz bu yazıyı okumanızı önemle tavsiye ederim. Aslında, sık sık yanlış yorumlanmaları nedeniyle, bunları bilseniz bile yazıyı yine de okumanızı tavsiye ederim.
Güven aralıkları (confidence intervals)
Güven aralıkları, parametre tahmini/kestirimi yapmanın sıklıkçı yoludur ve bir nokta tahmininden daha fazlasıdır. Güven aralıkları oluşturmanın arkasındaki teknik ayrıntılar bu yazının kapsamı dışındadır, ancak genel düzeyde bilgi vereceğim.
Kendinizi bir ortalama değer (mean value) (bir popülasyondaki ortalama boy, iki grup arasındaki ortalama IQ farkı vb.) tahmin etmeye çalışan bir kişinin yerine koyun. Her zamanki gibi, popülasyondan örnek veriler alarak başlarsınız. Şimdi, bir sonraki adım size bahsetmediğim sihirli adımdır. Bu, bir değer aralığını hesaplamak için standart bir prosedürdür.
Herhangi bir veri almadan önce, örneklem boyutu da dahil olmak üzere tüm prosedürü belirlersiniz. Ve prosedürü aşağıdaki hedefi göz önünde bulundurarak seçersiniz:
Varsayımsal/farazi olarak, prosedürü çok sayıda tekrarlarsanız, güven aralığı belirli bir olasılıkla gerçek ortalamayı içermelidir.
İstatistiklerde, yaygın olarak kullanılanlar %95 ve %99 güven aralıklarıdır.
Sabit ortalamaya sahip bir popülasyon seçerseniz, örnek verileri alırsanız ve son olarak %95 güven aralığını hesaplarsanız, hesaplamaların %95’inde hesaplanan aralık gerçek ortalamayı kapsayacaktır.
Bir güven aralığı hesapladıktan sonra, bu aralığın %95 olasılıkla gerçek ortalamayı kapsadığını söylemek yanlıştır (bu yaygın bir yanlış yorumdur). Sadece, uzun dönemde, aynı prosedürü izleyerek elde ettiğiniz güven aralıklarının %95'inin gerçek ortalamayı kapsayacağını önceden/baştan söyleyebilirsiniz.
Güven aralıklarının hesaplanmasının grafiksel bir gösterimi
Yukarıda tarif edilen prosedürü gösteren kısa bir animasyonu başlatmak için aşağıdaki resme tıklayın: 
Animasyonu başlatmak / yeniden başlatmak için resmin üzerine tıklayın.
Gerçek sayı çizgisinin üzerinde bir yerde, varsayımsal/farazi bir ortalamamız bulunuyor (ortalama, 'm' harfi ile kısaltılmıştır). Ardışık olarak 20 adet %95’lik güven aralığı oluşturuyoruz. Bunlardan ikisi ortalamayı kaçırıyor ve 18'i içeriyor. Bu 18/20 = %90 oranını verir.
Neden güven aralıklarının %95'i değil de sadece %90'ı ortalamayı kapsıyor? Cevap, elbette, sürecin doğal olarak olasılıksal olmasında ve herhangi bir sabit sayıdaki güven aralığının tam olarak %95'inin gerçek ortalamayı kapsayacağının garantisinin olmamasında yatıyor. Bununla birlikte, üretilen aralıkların sayısı arttıkça, ortalamayı kapsayan yüzde, %95'e daha da yaklaşır.
Bu arada, güven aralıklarının aynı genişliğe sahip olmadığına ve hepsinin farklı değerler etrafında merkezlendiğine dikkat edin.
Özet
Bu yazıda, tanımlayıcı ve çıkarımsal istatistikler arasındaki farktan bahsettim ve çıkarımsal istatistiğin 3 hedefini açıkladım:
- Parametre tahmini/kestirimi
- Veri tahmini/öngörüsü
- Model karşılaştırması
Son hedeften fazla bahsetmedim ve çoğunlukla ilkine odaklandım.
Sıklıkçı ve Bayesci yaklaşımlar arasındaki farkın, bu ikisinin olasılık kavramını farklı şekillerde tanımlamasından kaynaklandığını gösterdim. Sıklıkçı istatistik sadece rastgele olayları olasılıkla ele alır ve sabit fakat bilinmeyen değerlerde belirsizliği (parametrelerin gerçek değerlerindeki belirsizlik gibi) nicelendirilebilir/hesaplanabilir bulmaz. Diğer yandan Bayesci istatistik, bir parametrenin olası değerleri üzerinde olasılık dağılımlarını tanımlar, bu dağılımlar da daha sonra başka amaçlar için kullanılabilir.
Son olarak, parametrelere olasılık-temelli yaklaşılmadığında, sıklıkçıların belirsizliği, tahmin edilen parametreyi boş (null) bir değerle (NHST) karşılaştırma veya güven aralıkları hesaplama seçeneklerinden biriyle uzun dönem hata oranlarını sınırlandırarak hallettiğini/ele aldığını gösterdim.
İlgili Dosyalar: BAYES TEOREMİ, İSTATİSTİK
Etiketler: GÜVEN ARALIĞI, NULL HİPOTEZİ, P-DEĞERİ, PARAMETRE TAHMİNİ/KESTİRİMİ
SORULAR:
ESHA DESHPANDE diyor
13 Aralık 2017, 9:14 pm
Yazının bu kısmını anlamama yardım eder misin?
“Diğer taraftan Bayesçilere göre, olası parametre değerleri üzerinde tam bir ardıl (posterior) dağılım mevcuttur; bu da tahmini sadece en olası değere dayandırmak yerine, tam ardıl (posterior) dağılımın integralini alarak tahmindeki belirsizliği hesaba katma imkanı sağlar”
cevap
CTHAEH diyor ki
14 Aralık 2017, 5:45 am
Selam Esha. Bu zor bir konu ve bu konuyla ilk karşılaştığımda benim de anlamam zaman aldı.
Bu temelde, bilinmeyen ancak sabit değerleri olan parametrelere olasılık atamayı (bu parametrelerin olasılığı olabileceğini) reddeden Sıklıkçılara dayanır (neden bahsettiğimi görmek için yukarıdaki Parametre tahmini ve veri tahmini bölümüne bakın). Oysa bu tür olasılıkları atamakta (felsefi) bir problem görmeyen Bayesçiler parametrenin olası değerleri üzerinden tüm olasılık dağılımını elde edebilirler.
Diyelim ki, hepsi "tura" yönünde rastgele bir biasa (eğilime/meyile) sahip bozuk paralarla dolu bir çantadan tek bir para çektiğiniz bir oyun oynuyorsunuz. Bias (eğilim/meyil), 0 ile 1 arasında bir sayıdır ve bu sayı, ilgili madeni para havaya atıldığında “tura” gelme olasılığını tanımlıyor (mesela bias değerinin 0,4 olması, parayı attığınızda “tura” gelme olasılığının 0,4 olduğu anlamına gelir).
Parayı 1000 kez atmanıza izin veriliyor, daha sonra sıradaki atış için "yazı" veya "tura" gelmesi üzerine bir bahis yapacaksınız ve parayı bir kez daha atacaksınız. 1001'inci atışın sonucunu doğru tahmin ederseniz, paranızı ikiye katlayacaksınız, aksi takdirde hepsini kaybedeceksiniz.
Muhtemelen yapacağınız şey ilk 1000 atışın sonuçlarını kaydetmek ve paranın bias’ını (meyil) tahmin etmeye çalışmak olur. Bias tahmininiz/hesabınız 0,5'ten fazlaysa, “tura” lehine (aksi takdirde “yazı” lehine) bahis oynarsınız.
Bias’ı tahmin ettiğiniz/hesapladığınız bölüme parametre tahmini/kestirimi denir. Parametre kestirimine Bayesçi ve Sıklıkçı yaklaşımlar sadece kullandıkları spesifik teknikler açısından değil, daha da önemlisi, kestirim sonucunda da farklılık gösterir. Bayesçiler, paranın bias’ının olası değerlerine bir olasılık atama konusunda sorun görmedikleri için, olası değerler üzerinden tüm olasılık dağılımını elde edebilirler. Bu nedenle “paranın bias’ının 0,5 olma olasılığı nedir?” gibi sorulara cevap verebilirler. Sıklıkçılar bunu yapmazlar. Bunun yerine, bias ile ilgili tahminleri tek bir sayı olur ve bu değer üzerindeki belirsizliği ölçemezler/belirleyemezler.
Örneğin, 10 atıştan 4’ü tura gelse de bir milyon atıştan 400.000’i tura gelse de, maksimum olabilirlik tahmini 0,4 olacaktır. Ancak, tabii ki ikinci durumda tahmininize çok daha fazla güvenirsiniz, bu da doğal olarak posterior (ardıl) olasılık dağılımına yansıtılır (ve onun ortalamayı merkez alan dar bir aralıkta yer almasına neden olur).
Sıklıkçılar bu sorunu kısmen çözmek için güven aralıkları (confidence interval) kullanırlar. Para atma sayısı daha yüksek olduğunda, aralığın kapsadığı değer aralığı çok daha dar olacaktır. Ancak, bu güven aralığı içinde, yine de farklı değerler için 'olabilirlik' ölçüsü/tahmini olmayacaktır. Başka bir deyişle, güven aralığınız [0,3 - 0,5] ise, bu aralıktaki her değer, bias’ın gerçek değeri olmak için eşit derecede iyi bir adaydır. Para atma sayısı düşük olduğunda, bu büyük bir fark yaratabilir.
Dediğim gibi, bu zor bir konudur ve sorunuzu tam olarak cevaplayamamış olabilirim. Lütfen daha fazla açıklama istemekten çekinmeyin!

